Unraveling CUDA DDP: How Distributed GPUs Collaborate to Accelerate Deep Learning
Unraveling CUDA DDP: How Distributed GPUs Collaborate to Accelerate Deep Learning
Read on Medium
Introduction
CUDA Distributed Data Parallel (DDP) is a potent tool for accelerating deep learning by distributing computations across multiple GPUs and machines. DDP ensures efficient gradient synchronization, allowing model updates across GPUs to remain consistent, which is critical for large-scale deep learning tasks. Understanding the mechanics of gradient synchronization, batch size effects, and learning rate adjustments in distributed settings is essential to leverage DDP’s full potential.
In this article, we will delve into the mathematical principles that guide gradient synchronization, explore how DDP affects model updates, and provide a basic implementation of DDP in PyTorch.
Section 1: Gradient Synchronization
In DDP, each GPU processes a different subset of the input data and computes gradients independently. These gradients are synchronized across all GPUs to ensure consistent model updates. The process of synchronization involves an all-reduce operation, where gradients from each GPU are aggregated and averaged to form a global gradient.
Mathematical Foundation
If we have N GPUs, each computing a gradient gᵢ based on its subset of the data, the global gradient G is calculated as:
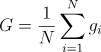
This global gradient is then used to update the model parameters using an optimizer. By averaging gradients across GPUs, DDP ensures that the model is updated consistently, regardless of the number of GPUs involved.
Section 2: Impact on Model Updates
2.1 Batch Size Considerations
In a single-GPU setup, the gradient is computed based on a batch size B. In a multi-GPU setup with N GPUs, each GPU processes a smaller batch size of B/N, and the gradients are averaged across GPUs. Effectively, this scales the gradient by 1/N.
2.2 Learning Rate Adjustments
To maintain training dynamics equivalent to a single-GPU setup, the learning rate is typically scaled by N. This compensates for the reduced gradient scale per GPU. Without adjusting the learning rate, the model may converge too slowly or incorrectly when training is distributed.
Section 3: Static vs. Dynamic Graphs
DDP supports both static and dynamic computation graphs. Static graphs, where the architecture and flow remain unchanged, allow for more efficient gradient computation and synchronization. Dynamic graphs, which are more flexible, may introduce overhead due to frequent gradient re-calculations and synchronization adjustments.
Section 4: Example Implementation
Here’s a basic example of implementing DDP in PyTorch:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
# Initialize DDP
dist.init_process_group("nccl", init_method='tcp://localhost:1088', rank=0, world_size=1)
# Define the model and move it to the GPU
model = ...
ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[0])
# Define the loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# Training loop
for inputs, labels in dataset:
inputs, labels = inputs.to(0), labels.to(0)
outputs = ddp_model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
In this simplified implementation, the DDP model synchronizes gradients across GPUs during backpropagation to ensure consistent parameter updates.
Conclusion
CUDA DDP optimizes deep learning training by distributing computations across multiple GPUs and ensuring synchronized gradient updates. Understanding how gradient synchronization affects model updates, particularly with regard to batch sizes and learning rates, allows developers to maximize DDP’s efficiency. With this knowledge, developers can implement more scalable and faster distributed training, leading to quicker convergence and better overall performance in their deep learning applications.