Understanding Backpropagation: A Deep Dive into the Core of Neural Network Training
Understanding Backpropagation: A Deep Dive into the Core of Neural Network Training
Read on Medium
Introduction
Backpropagation is a fundamental algorithm in the training of artificial neural networks, enabling models to learn by updating their weights in response to errors made on training data. Alongside backpropagation, concepts like learning rates, schedulers, and optimizers play crucial roles in determining the efficiency and effectiveness of training. Despite their importance, these topics can often seem opaque, particularly the mathematical principles that underpin them.
In this article, we will delve deep into the intricacies of backpropagation, elucidate the function of learning rates, explore how schedulers can adjust learning rates dynamically, and discuss the various optimizers that enhance the training process. We will also include relevant examples, mathematical derivations, and PyTorch code snippets to solidify your understanding.
Section 1: Explanation and Background
1.1 What is Backpropagation?
Backpropagation, short for “backward propagation of errors,” is an algorithm to train neural networks by minimizing the error, or loss, between the prediction and the actual output. The central idea behind backpropagation is to propagate the error backward through the network, allowing each neuron to adjust its weights to reduce this error.
Mathematical Foundation
The mathematical basis of backpropagation lies in calculus, specifically the chain rule. The chain rule allows us to compare a composite function's derivative by multiplying its individual components' derivatives.
Consider a simple neural network with a single neuron. The neuron has an input x, a weight w, and a bias b. The output of the neuron is given by:
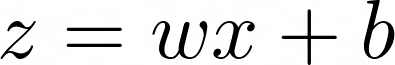
This output is passed through an activation function f(z) to produce the final output ŷ:
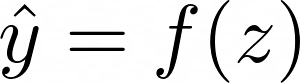
The loss L is calculated using a loss function, such as mean squared error (MSE), which compares the predicted output ŷ to the true output y:
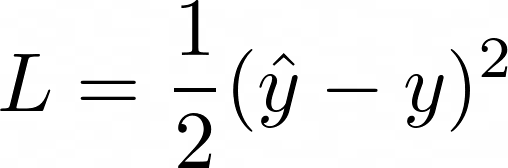
To minimize the loss, we need to update the weight w. This is where the gradient of the loss function with respect to w comes into play. Using the chain rule, the gradient can be computed as follows:
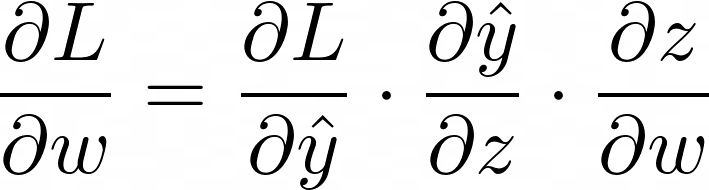
Multiplier 1 is the derivative of the loss with respect to the predicted output, multiplier 2 is the derivative of the activation function with respect to the neuron’s output, and multiplier 3 is the derivative of the weighted sum with respect to the weight.
Thus, the entire gradient is:
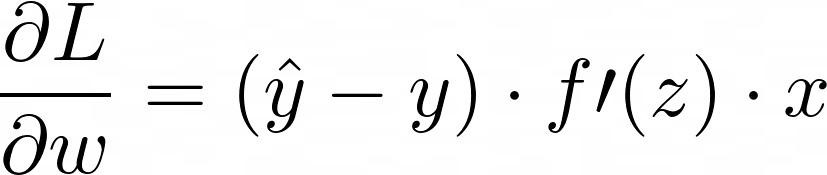
This gradient tells us how much weight we need and in what direction to adjust it to decrease the loss.
Backpropagation in a Multi-Layer Network
For a network with multiple layers, backpropagation works similarly, but the process becomes more complex. Each layer’s weights are updated by propagating the gradients back through the network, layer by layer. This is done by calculating the gradient of the loss with respect to the weights in each layer and using these gradients to update the weights.
Let’s consider a simple two-layer neural network:
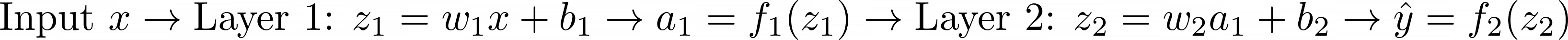
Here, w₁ and w₂ are the weights, b₁ and b₂ are the biases, f₁ and f₂ are the activation functions, and a₁ is the output of the first layer.
The loss is again computed as:
The gradients are calculated in reverse order, starting from the output layer and moving back to the input layer:
**Step 1: **Compute the gradient of the loss with respect to the output layer’s weights w₂:
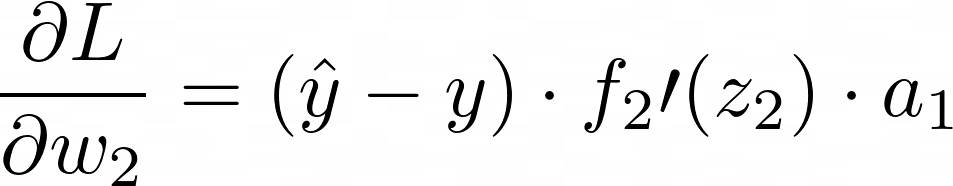
Step 2: Compute the gradient of the loss with respect to the first layer’s weights w₁:
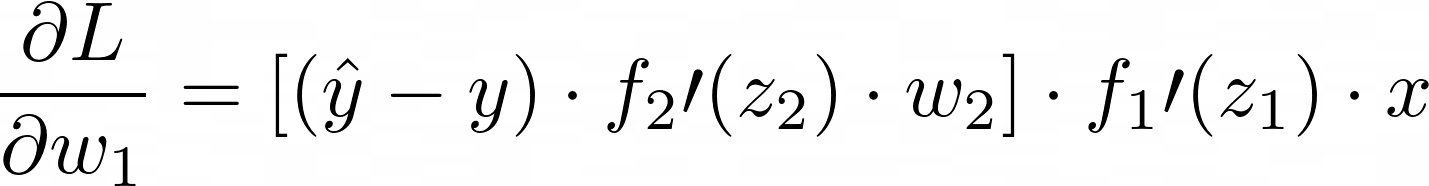
The weight updates are then performed using these gradients, typically using gradient descent (discussed later in this article).
Code Snippet: A Simple Backpropagation Implementation
import torch
# Define a simple two-layer neural network
class SimpleNN(torch.nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = torch.nn.Linear(2, 2)
self.fc2 = torch.nn.Linear(2, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Initialize model, loss function, and optimizer
model = SimpleNN()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Sample data
inputs = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
targets = torch.tensor([[1.0], [2.0]])
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward pass and weight update
loss.backward()
optimizer.step()In this example, the model consists of two layers and the loss is computed using mean squared error. The backward() function computes the gradients and the optimizer.step () updates the weights.
Conclusion
Backpropagation is a powerful and essential algorithm in the field of deep learning, enabling neural networks to learn from data by systematically adjusting their weights to minimize errors. By understanding the underlying mathematical principles and how backpropagation operates within simple and complex networks, you gain valuable insights into how neural networks are trained.
This foundational knowledge, combined with practical implementations such as the PyTorch example provided, equips you to apply backpropagation effectively in your projects. As you continue to explore advanced topics like learning rates, schedulers, and optimizers, remember that mastering the basics is the key to unlocking the full potential of deep learning.